
ここでは、pandasのstack()およびunstack()メソッドを解説していきます。
どちらもデータを自由に変形するメソッドです。
stack()とunstack()
stackとunstackはどちらも行か列を回転させるメソッドです。
- stackはデータ内の各列を行にもってくる。
- unstackはデータ内の各行を列にもってくる。
このように、stackとunstackは逆の処理になっています。
つまり、stackした結果に対してunstackを実行すると、元に戻ると言うことですね。

これから具体例を見ていきますが、ざっくり、以下のように把握しておきましょう。
- stack:実行すると、縦に長くなる。(列だったものが、行になるので。)
- unstack:実行すると、横に長くなる。(行だったものが、列になるので。)
「どっちがどっちだっけ?」となる時があります。
stackというのは「積み重ねる」と言う意味がある、つまり縦に長くなる、、、ってことは列を行にするのがstackだ!と連想できます。
では、具体的に見ていきましょう。
stack()
stackは各列を行に回転させます。
具体例で見ていきましょう。
以下のように、生徒のテスト結果を表すデータがあるとします。
| math | English | science | |
|---|---|---|---|
| Larissa | 77 | 42 | 90 |
| Jaylan | 89 | 43 | 98 |
| Golda | 45 | 47 | 65 |
| Myriam | 75 | 70 | 51 |
これに対してstackを実行すると、以下のようになります。
各列「math、English、science」は列の要素となります。
| Larissa | math | 77 |
|---|---|---|
| English | 42 | |
| science | 90 | |
| Jaylan | math | 89 |
| English | 43 | |
| science | 98 | |
| Golda | math | 45 |
| English | 47 | |
| science | 65 | |
| Myriam | math | 75 |
| English | 70 | |
| science | 51 |
図解で表すと、以下のようになります。

列だった要素が行になるので、当然、その分行数は増えます。結果として、縦に長いデータになります。
では、コードで見てみましょう。
df = pd.DataFrame(
[[77, 42, 90], [89, 43, 98], [45, 47, 65], [75, 70, 51]],
columns=['math', 'English', 'science'],
index=['Larissa', 'Jaylan', 'Golda', 'Myriam'],
)
result = df.stack()
result
結果は以下のようになります。
Larissa math 77
English 42
science 90
Jaylan math 89
English 43
science 98
Golda math 45
English 47
science 65
Myriam math 75
English 70
science 51
dtype: int64
ここではstackの結果はpd.Series型になっています。IndexはMultiIndexになっています。
階層インデックスで表現されていると言うことですね。
type(result) # pandas.core.series.Series result.index
結果は以下となります。
MultiIndex([('Larissa', 'math'),
('Larissa', 'English'),
('Larissa', 'science'),
( 'Jaylan', 'math'),
( 'Jaylan', 'English'),
( 'Jaylan', 'science'),
( 'Golda', 'math'),
( 'Golda', 'English'),
( 'Golda', 'science'),
( 'Myriam', 'math'),
( 'Myriam', 'English'),
( 'Myriam', 'science')],
)
unstack()
unstackは各行を列に回転させます。
先ほどの例を使ってみてみましょう。
| Larissa | math | 77 |
|---|---|---|
| English | 42 | |
| science | 90 | |
| Jaylan | math | 89 |
| English | 43 | |
| science | 98 | |
| Golda | math | 45 |
| English | 47 | |
| science | 65 | |
| Myriam | math | 75 |
| English | 70 | |
| science | 51 |
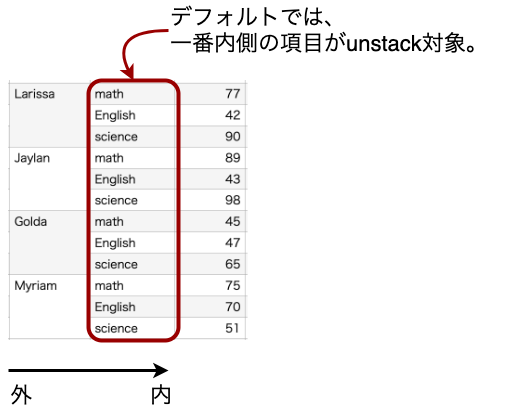
上記のデータについて、unstackを実行すると以下のようになります。
行の項目だった「math、English、science」が列となります。(デフォルトでは、最も内側の行の項目が列になります。)
| math | English | science | |
|---|---|---|---|
| Larissa | 77 | 42 | 90 |
| Jaylan | 89 | 43 | 98 |
| Golda | 45 | 47 | 65 |
| Myriam | 75 | 70 | 51 |
図解で見てみましょう。

stackとは逆に、行だった要素が列になります。その分列数は増えます。結果として、横に長いデータになります。
ソースコードを見てみましょう。
df = pd.DataFrame(
[[77, 42, 90], [89, 43, 98], [45, 47, 65], [75, 70, 51]],
columns=['math', 'English', 'science'],
index=['Larissa', 'Jaylan', 'Golda', 'Myriam'],
).stack()
df.unstack()
結果は以下となります。(df.stack().unstack()で元の形に戻ることを確認してみてください。)
| math | English | science | |
|---|---|---|---|
| Larissa | 77 | 42 | 90 |
| Jaylan | 89 | 43 | 98 |
| Golda | 45 | 47 | 65 |
| Myriam | 75 | 70 | 51 |
「あれ?今回の行は階層インデックになっていたよね?どの階層のインデックスを列に持ってくるか勝手に決まるの?」と疑問に思ったかもしれません。
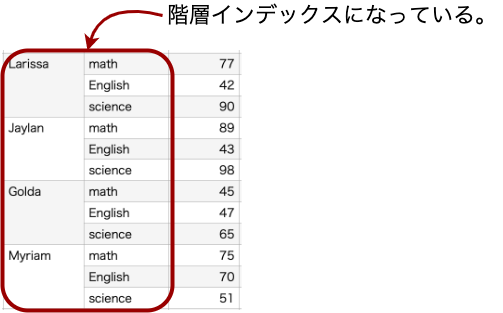
unstack()は、デフォルトでは一番内側の項目が処理の対象になります。
今回は、科目(subject)が一番内側にあったため、それがunstack対象として列になりました。
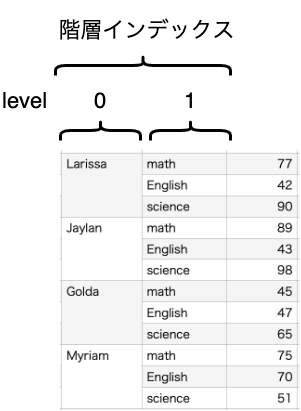
しかし、これはunstackの引数で指定できます。
公式ドキュメントではlevelと定義されていますが、そのlevelの番号を渡します。
levelは一番外側が「0」です。内側に行くにつれて連番で増えます。
では、実際に指定してみましょう。
今回は「0」の生徒の名前を行とします。結果を予想してみてください。
df = pd.DataFrame(
[[77, 42, 90], [89, 43, 98], [45, 47, 65], [75, 70, 51]],
columns=['math', 'English', 'science'],
index=['Larissa', 'Jaylan', 'Golda', 'Myriam'],
).stack()
df.unstack(0)
結果は以下となります。
| Larissa | Jaylan | Golda | Myriam | |
|---|---|---|---|---|
| math | 77 | 89 | 45 | 75 |
| English | 42 | 43 | 47 | 70 |
| science | 90 | 98 | 65 | 51 |
予想通りでしたか?
生徒の名前が列になりました。そして、一番内側のインデックスだった科目名(subject)が新たにインデックスになりましたね。
もちろん、このように処理対象の項目の指定はunstackだけではなく、stackでも可能です。
まとめ
日々いろいろなデータが蓄積していきますね。
時にはJSONだったり、CSVだったり、、、
そして、それらのデータを組み合わせて分析したいとき、データの形を整える必要があります。
pandasはデータを粘土のように自由自在に変形する力を与えてくれます。

stackやunstack、pivot_tableなども組み合わせれば、たくさんの種類のデータの形を整え、比較や結合して新しい発見が得られるかもしれません。
しかし、そのためには「どのように変換すれば欲しい形になるかな?」と頭のなかで想像を巡らす必要があります。
今回様々な図解を紹介しました。
このような図を頭のなかで描いて、「こうして、ああして、こうすれば使いやすい形になるぞ!」と具体的なアルゴリズムがパッと浮かぶようになりたいものですね!
参考図書

NumPyやpandas、Matplotlibなどを使ったデータ分析の方法が体系的にまとまっています。
Pythonはデータ分析向けのライブラリが豊富です。1つ1つを詳細に覚えていくのは難しいですよね。
ですので、まずはこの本を使って全体をざっくり体系的に見ていくとやりやすいと思いました。