※この記事は「AWSでサーバーレスなバッチ処理を作るハンズオン」の5章です。こちらの記事からスタートできます。

今回は「AWSでサーバーレスなバッチ処理を作るハンズオン」の最終章ということで、これまで雑多に書いてきたLambda関数をリファクタリングしていきます。
具体的には、以下のような修正をして完成させます。
- S3、DynamoDBに関する処理をLambdaレイヤーとして切り出し、共通化
- 切り出したLambdaレイヤーに対するユニットテストを作成
- Integrationテストを作成
さっそくやっていきましょう!
ソースコード
今回のリファクタリングについては変更点が多いため、ブランチを分けています。
以下のURLよりrefactoringというブランチを閲覧することで、完成版のソースコードを見ることができます。
なお、見やすくなるようにコミットを分割しました。
必要に応じて差分などを確認してください。
共通する処理をLambdaレイヤーとして切り出す
今回のLambdaレイヤーには以下の3つの要素を含めることにします。
- S3に関する処理
- DynamoDBに関する処理
- Message(Model)
Lambdaレイヤーの準備
では、早速Lambdaレイヤー用のディレクトリを作成しましょう。
mkdir -p functions/layer/python
このディレクトリに共通化する処理を追加していくことにします。
なお、ディレクトリの名前をpythonとしておくと、Lambda関数にこのレイヤーがアタッチされた際に自動的にパスが通ります。Pythonコードos.path.join書かなくても参照できると言うことですね。
続いて、template.yamlにLambdaレイヤーを追加しましょう。
以下の記述を追加します。
PythonCommonModuleLambdaLayer: Type: AWS::Serverless::LayerVersion Properties: Description: "Original common library of this app." ContentUri: functions/layer/python CompatibleRuntimes: - python3.8 Metadata: BuildMethod: python3.8
さらに、MakeReportFunction及びHtmlToPdfFunctionのリソースにこのレイヤーを追加する.
MakeReportFunction: Type: AWS::Serverless::Function Properties: CodeUri: functions/make_report/ Handler: app.lambda_handler Layers: <---------------------------------- 追加 - !Ref PythonCommonModuleLambdaLayer <----- 追加 Environment: ...省略 HtmlToPdfFunction: Type: AWS::Serverless::Function Properties: CodeUri: functions/html_to_pdf/ Handler: app.lambda_handler Layers: - !Ref WkhtmltopdfLambdaLayer - !Ref PythonCommonModuleLambdaLayer <---- 追加 Environment: ...省略
これでLambdaレイヤーを開発する準備が整いました。
S3に関する処理の共通化
今回はデータを保存する関係のモジュールをstorageという名前にしましょう。
関連するファイルを作成します。
mkdir -p functions/layer/python/storage
touch functions/layer/__init__.py
touch functions/layer/python/__init__.py
touch functions/layer/python/storage/{__init__.py,storage.py,s3.py,minio.py}
storage.py
最初にstorage.pyを書いていきます。これはオブジェクト指向でいうところのInterfaceの役割となるクラスです。
PythonにはInterfaecがないため、抽象クラスとして宣言します。
from abc import ABCMeta, abstractmethod class Storage(metaclass=ABCMeta): @abstractmethod def upload_file(self, file_path: str, object_name: str) -> str: pass @abstractmethod def download_file(self, object_name: str, dist_dir: str) -> str: pass
upload_file()は指定したファイルをアップロードするメソッド。download_fileはオブジェクトストレージ上にある特定のオブジェクトをダウンロードするメソッド。
s3.py
s3.pyはStorageクラスを継承しています。実際にS3に対して処理を行う具象クラスです。
from typing import Any import os import boto3 from .storage import Storage class S3(Storage): bucket_name: str s3: Any bucket: Any def __init__(self, bucket_name: str, **kwargs) -> None: super().__init__() self.s3 = boto3.resource("s3", **kwargs) self.bucket = self.s3.Bucket(bucket_name) self.bucket_name = bucket_name def upload_file(self, file_path: str, object_name: str) -> str: self.bucket.upload_file(file_path, object_name) return object_name def download_file(self, object_name: str, dist_dir: str) -> str: object_path = os.path.join(dist_dir, os.path.basename(object_name)) self.bucket.download_file(object_name, object_path) return object_path
minio.py
今回、ローカルでの開発にはMinioを利用しています。
実際、MinioはS3のAPIと互換性があるため別のクラスにする必要はありませんが、明示的にアクセストークンなどを指定する必要があるということで、切り分けてみました。
しかし、実態はS3クラスを継承しているため、コンストラクタのみ違うだけです。
from .s3 import S3 class Minio(S3): def __init__( self, bucket_name: str, endpoint_url: str = None, access_key_id: str = None, secret_access_key: str = None, ) -> None: super().__init__( bucket_name, endpoint_url=endpoint_url, aws_access_key_id=access_key_id, aws_secret_access_key=secret_access_key, )
ユニットテストの作成
では、先ほど作成したs3.pyのユニットテストを書いていきます。
その前に、予め不要なファイルを削除しておきましょう。
rm -f tests/unit/test_buyer.py rm -f tests/unit/test_checker.py rm -f tests/unit/test_seller.py
では、関連するファイルを作って行きます。
mkdir -p tests/unit/layer/python/storage touch tests/unit/layer/__init__.py touch tests/unit/layer/python/__init__.py touch tests/unit/layer/python/storage/__init__.py touch tests/unit/layer/python/storage/test_s3.py
そして、事前にユニットテストに必要なモジュールをインストールしておきます。
pip3 install -r tests/requirements.txt
続いて、tests/__init__.pyにLayerのコードを読み込む記述を追加します。
import sys import os sys.path.append(os.getcwd() + "/functions/layer/python")
なぜこの記述が必要なのかというと、ローカルでテストを実行する際にLambdaレイヤーとして書いたコードが自動でPythonのパスに追加されないからです。
Lambdaレイヤーのディレクトリを作成した際に少し触れましたが、pythonという名前のディレクトリでLambdaレイヤーを作成した場合、そのディレクトリの内容は自動でPythonのパスに追加されます。
ですので、実際にAWS上で実行される場合は問題ないものの、ローカルのテストを行う場合はそのような機構がないため、__init__.pyにパスを追加する記述を書いて対応すると言うことですね。
tests/unit/layer/python/storage/test_s3.pyの内容は以下になります。
from typing import Dict import os import uuid from storage.s3 import S3 def configure_mock(mocker, config={}) -> Dict: mock_bucket = mocker.MagicMock() default = { "upload_file.return_value": True, "download_file.return_value": True, } if "Bucket" in config: default.update(config["Bucket"]) mock_bucket.configure_mock(**default) mock_s3 = mocker.MagicMock() default = { "Bucket.return_value": mock_bucket, } if "S3" in config: default.update(config["S3"]) mock_s3.configure_mock(**default) mocker.patch("boto3.resource", return_value=mock_s3) return { "Bucket": mock_bucket, "S3": mock_s3, } def test_upload_file(mocker): mock_bucket = configure_mock(mocker)["Bucket"] file_path = str(uuid.uuid4()) object_name = str(uuid.uuid4()) s3 = S3("some_bucket") result = s3.upload_file(file_path, object_name) assert result == object_name mock_bucket.upload_file.assert_called_with(file_path, object_name) def test_download_file(mocker): mock_bucket = configure_mock(mocker)["Bucket"] dist_dir = os.path.join("tmp", "download") object_name = "11_28.html" expected_path = os.path.join("tmp", "download", "11_28.html") s3 = S3("some_bucket") result = s3.download_file(object_name, dist_dir) assert result == expected_path mock_bucket.download_file.assert_called_with(object_name, expected_path)
今回はユニットテストなので、boto3をモック化して指定のメソッドが仕様通りに呼ばれていることのみテストしています。
実際にアップロードされたかどうかまでテストしたい場合は、boto3をモック化せずに本当に呼び出したのち、エラー無くアップロードされたことを確認するコードを書くと良いでしょう。
今回は、実際にアップロードされたかなどはIntegrationテストとして書いていくことにしましょう。
では、テストを実行してみましょう。
python3 -m pytest tests/unit/layer -v
DynamoDBに関する処理を共通化
実質DynamoDBを利用するのはMakeReportFunctionだけですが、ここでは再利用性やよりきれいな構造を目指して共通化してみましょう。
Modelの準備
今回はDynamoDBに格納するデータをmessageというモデルとして表現してみます。
mkdir functions/layer/python/model
touch functions/layer/python/model/{__init__.py,model.py,message.py}
model/model.pyはS3を共通化するときに書いたstorage.pyと同じで、抽象クラスです。
from abc import ABCMeta class Model(metaclass=ABCMeta): pass
Modelという抽象クラスを作成しますが、今回は特にメソッドはありません。
一見不要に感じますが、以下の理由で作成しておく意義があると思います。
Modelという抽象度で処理を書ける。- 全
Modelが共通でもつべきメソッドが必要になった時に簡単に対処可能。
では、さっそくmodel/message.pyにModelの具象クラスとなるMessageクラスを書いていきます。
from dataclasses import dataclass from datetime import date from model.model import Model @dataclass class Message(Model): date: date message: str
こちらはシンプルなdataclassとしています。
dateはDynamoDBのキーとして定義しましたね。
注意)設計によってはデータベースのテーブルなどの構造に依存するものをModel、それに依存せず、そのシステム間でのデータの受渡用のオブジェクトとしてEntityとして分けることもあります。今回は簡単のためシステム間のデータの受渡にもこのModelを使います。
repository.py
今回はデータベース関係のモジュールをrepositoryという名前で共通化しましょう。
まずは必要なファイルを作成していきます。
mkdir functions/layer/python/repository
touch functions/layer/python/repository/{__init__.py,repository.py,dynamodb.py}
repository.pyにはRepositoryクラスがありますが、こちらは例によって抽象クラスです。
from abc import ABCMeta, abstractmethod from datetime import date from model.message import Message class Repository(metaclass=ABCMeta): @abstractmethod def get_message(self, target_date: date) -> Message: pass
get_message()はtarget_dateで指定したキーに基づいてデータを取得し、Messageというモデルで返すメソッドです。
dynamodb.py
そして、以下がRepositoryの具象クラスであるDynamoDBクラスです。
from datetime import date from botocore.exceptions import ClientError import boto3 from model.message import Message from .repository import Repository class DynamoDB(Repository): def __init__(self, table_name, endpoint_url=None): self.dynamodb = boto3.resource("dynamodb", endpoint_url=endpoint_url) self.table_name = table_name self.table = self.dynamodb.Table(table_name) self.cache = {} def get_message(self, target_date: date) -> Message: str_date = target_date.strftime("%Y/%m/%d") try: response = self.table.get_item(Key={"Date": str_date}) except ClientError as e: print(e.response["Error"]["Message"]) raise e else: if "Item" in response: return Message(date=target_date, message=response["Item"]["Message"]) return None
ユニットテストの作成
では、DynamoDBクラスのユニットテストを書いていきましょう。
必要なファイルを作成します。
mkdir -p tests/unit/layer/python/repository
touch tests/unit/layer/python/repository/{__init__.py,test_dynamodb.py}
test_dynamodb.pyの中身は以下です。
こちらもS3の時と同様、boto3をモック化して必要なメソッドが正しく呼ばれているかどうかのチェックのみ行っています。
import datetime import pytest from repository.dynamodb import DynamoDB def configure_mock(mocker, mock_table_config_override={}): mock_db = mocker.MagicMock() mock_table = mocker.MagicMock() mock_table.configure_mock( **{ "get_item.return_value": mock_table_config_override.get( "get_item.return_value", {"Item": {"Attribute": True}} ), } ) mock_db.configure_mock( **{ "Table.return_value": mock_table, } ) mocker.patch("boto3.resource", return_value=mock_db) return { "mock_db": mock_db, "mock_table": mock_table, } @pytest.fixture() def message(): return { "Date": "2021/11/28", "Message": "Hello, world!!", } def test_get_message(message, mocker): mock_table = configure_mock( mocker, mock_table_config_override={ "get_item.return_value": {"Item": message}, }, )["mock_table"] db = DynamoDB("some_table") target_date = datetime.datetime.strptime(message["Date"], "%Y/%m/%d") result = db.get_message(target_date) mock_table.get_item.assert_called_with(Key={"Date": message["Date"]}) assert result.date == target_date assert result.message == message["Message"]
では、テストを実行してみましょう。
python3 -m pytest tests/unit/layer -v
これでS3およびDynamoDBに関する処理を共通化したレイヤーの完成です。
次からは既存のコードを今回作ったレイヤーを利用するように書き換えます。
既存のコードをLambdaレイヤーを使ったコードに書き換え
では、既存のコードを書き換えて行きます。
Tips: Lambdaレイヤーにvscodeの入力補完(IntelliSense)が働かない!
Layerとして切り出したコードについてはそのままではvscodeの入力補完が働きません。
そこでプロジェクトの直下にある.vscode/settings.jsonに以下のような設定を追加しましょう。
"python.analysis.extraPaths": [ "functions/layer/python", ],
そうすることで、今回作成したLambdaレイヤーのコードを使うときにも入力補完が使えるようになります。
MakeReportFunction
最初に、MakeReportFunctionのapp.pyを書き換えましょう。
S3やDynamoDBに関する処理はLambdaレイヤーを利用できるため、コード量が削減しました。
import datetime import os import tempfile import pystache from repository.dynamodb import DynamoDB from repository.repository import Repository from storage.minio import Minio from storage.s3 import S3 from storage.storage import Storage class Config: @staticmethod def or_none(val): is_empty = val is None or val == "" return None if is_empty else val def __init__( self, bucket_name, dynamodb_table_name, s3_endpoint=None, dynamodb_endpoint=None, minio_user=None, minio_password=None, ): self.bucket_name = bucket_name self.dynamodb_table_name = dynamodb_table_name self.s3_endpoint = self.or_none(s3_endpoint) self.dynamodb_endpoint = self.or_none(dynamodb_endpoint) self.minio_user = self.or_none(minio_user) self.minio_password = self.or_none(minio_password) def get_target_date(): return datetime.date(2021, 11, 28) def get_object_name(target_date: datetime.date, ext=".html"): str_date = target_date.strftime("%Y_%m_%d") return f"{str_date}{ext}" def make_report(repo: Repository, storage: Storage, target_date, out_dir): template = """ <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Message</title> </head> <body> {{{ message }}} </body> </html> """ msg = repo.get_message(target_date) html = pystache.render(template, {"message": msg.message}) object_name = get_object_name(target_date) html_path = os.path.join(out_dir, os.path.basename(object_name)) with open(html_path, mode="w") as f: f.write(html) storage.upload_file(html_path, object_name) return object_name def get_repository(config: Config) -> Repository: return DynamoDB(config.dynamodb_table_name, endpoint_url=config.dynamodb_endpoint) def get_storage(config: Config) -> Storage: if config.s3_endpoint == "": return S3(config.bucket_name) else: return Minio( config.bucket_name, endpoint_url=config.s3_endpoint, access_key_id=config.minio_user, secret_access_key=config.minio_password, ) def lambda_handler(event, context): config = Config( bucket_name=os.environ.get("SSB_BUCKET_NAME"), dynamodb_table_name=os.environ.get("SSB_DYNAMODB_TABLE_NAME"), s3_endpoint=os.environ.get("SSB_S3_ENDPOINT"), dynamodb_endpoint=os.environ.get("SSB_DYNAMODB_ENDPOINT"), minio_user=os.environ.get("SSB_MINIO_USER"), minio_password=os.environ.get("SSB_MINIO_PASSWORD"), ) repo = get_repository(config) storage = get_storage(config) with tempfile.TemporaryDirectory() as temp_dir: object_name = make_report(repo, storage, get_target_date(), temp_dir) return { "BucketName": config.bucket_name, "ObjectName": object_name, }
lambda_handler()のなかでそれぞれget_repository()およびget_storage()を読んでいますが、この部分で具象クラスのオブジェクトをそれぞれ受け取ってます。
make_report()はRepositoryとStorageという抽象クラスに依存しているのがポイントです。
lambda_handler()の中でmake_report()に具象クラスを引数として渡すことで、依存性を注入する(Dependency Injection)しています。
HtmlToPdfFunction
つづいて、HtmlToPdfFunctionのapp.pyです。
こちらもS3に関する処理が削除されています。
import os import tempfile import pdfkit from storage.minio import Minio from storage.s3 import S3 from storage.storage import Storage class Config: @staticmethod def or_none(val): is_empty = val is None or val == "" return None if is_empty else val def __init__( self, s3_endpoint=None, minio_user=None, minio_password=None, wkhtmltopdf_path=None, ): self.s3_endpoint = self.or_none(s3_endpoint) self.minio_user = self.or_none(minio_user) self.minio_password = self.or_none(minio_password) self.wkhtmltopdf_path = self.or_none(wkhtmltopdf_path) def html_to_pdf(storage: Storage, object_name, out_dir, config: Config): html_path = storage.download_file(object_name, out_dir) pdf_path = os.path.join( out_dir, os.path.splitext(os.path.basename(object_name))[0] + ".pdf" ) options = { "enable-local-file-access": None, "header-right": "Simple Serverless Batch", "footer-right": "[page]/[topage]", } pdfkit_config = None if config.wkhtmltopdf_path: pdfkit_config = pdfkit.configuration(wkhtmltopdf=config.wkhtmltopdf_path) pdfkit.from_file(html_path, pdf_path, options=options, configuration=pdfkit_config) pdf_object_name = storage.upload_file(pdf_path, os.path.basename(pdf_path)) return pdf_object_name def get_storage(config: Config, bucket_name: str) -> Storage: if config.s3_endpoint == "": return S3(config.bucket_name) else: return Minio( bucket_name, endpoint_url=config.s3_endpoint, access_key_id=config.minio_user, secret_access_key=config.minio_password, ) def lambda_handler(event, context): config = Config( s3_endpoint=os.environ.get("SSB_S3_ENDPOINT"), minio_user=os.environ.get("SSB_MINIO_USER"), minio_password=os.environ.get("SSB_MINIO_PASSWORD"), wkhtmltopdf_path=os.environ.get("SSB_WKHTMLTOPDF_PATH"), ) bucket_name = event["BucketName"] html_object_name = event["ObjectName"] storage = get_storage(config, bucket_name) with tempfile.TemporaryDirectory() as temp_dir: pdf_object_name = html_to_pdf(storage, html_object_name, temp_dir, config) return { "BucketName": bucket_name, "ObjectName": pdf_object_name, }
Integrationテストの実装
では、最後にIntegrationテストを追加しましょう。IntegrationテストはAWS上で稼働している環境に対して行うこととします。
そのため、テスト中に必要になる各種AWSリソースの収集はboto3を使ってCloudFormationのスタックから行います。
さて、今回はプロジェクトを初期化した際にひな形として作成されているIntegrationテストのファイルを加筆/修正していく形で書いていくことにします。
ですので、編集するファイルはtests/integration/test_state_machine.pyです。
Integrationテストのフローチャート
今回のソースコードは比較的長くなるため、まずはじめに全体の流れをフローチャートで確認しておきましょう。
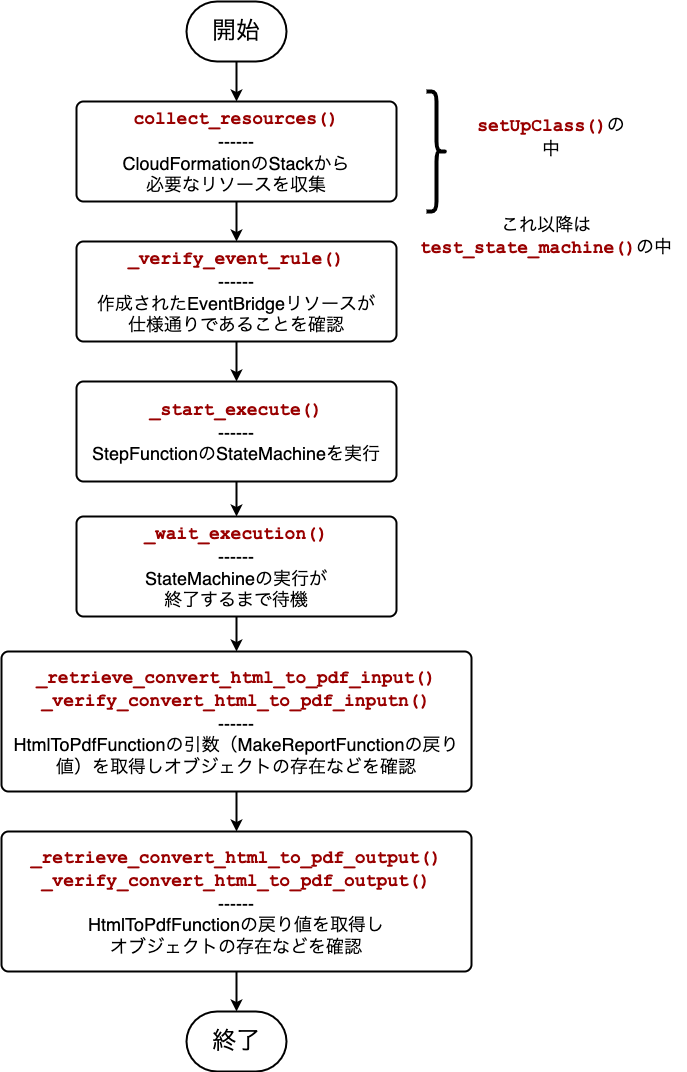
ポイントは次の通りです。
- デプロイしたリソースが正しく設定されていることを確認する。
- 実際にStateMachineを実行する。
- S3にアップロードできているかを確認している。
では早速ソースコードを見て行きましょう。
Integrationテストのソースコード
250行程度あり、かなり長いです。
今回はunittestパッケージのTestCaseを使っています。そのため、実行順序は以下のようになります。
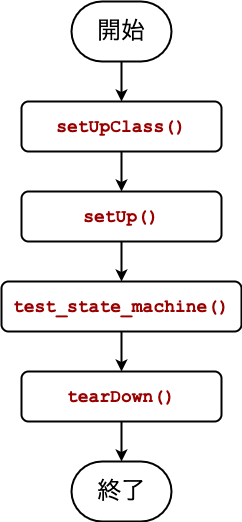
実際に写経するのは大変だと思いますので、フローチャートと照らし合わせつつ1メソッドずつ確認しながらコピペをすすめると良いと思います。
from time import sleep from typing import Dict, List from unittest import TestCase from uuid import uuid4 import json import logging import os from botocore.client import BaseClient import boto3 import botocore """ Make sure env variable AWS_SAM_STACK_NAME exists with the name of the stack we are going to test. """ class TestStateMachine(TestCase): dummy_message: str event_rule_name: str state_machine_arn: str transaction_table_name: str bucket_name: str client: BaseClient objects_to_delete: List[str] = [] def assert_object_exists(self, bucket_name: str, key: str): client = boto3.client("s3") try: client.head_object( Bucket=bucket_name, Key=key, ) except botocore.exceptions.ClientError as e: if e.response["Error"]["Code"] == "404": raise Exception( f"There is no object named '{key}' in s3 bucket '{self.bucket_name}': {e}" ) else: raise Exception(f"Something wrong with this request: {e}") except Exception as e: raise Exception(f"{e}") def put_item_for_test(self) -> dict: client = boto3.client("dynamodb") return client.put_item( TableName="Messages", Item={ "Date": {"S": "2021/11/28"}, "Message": {"S": self.dummy_message}, }, ) def delete_item_from_dynamodb_table(self): client = boto3.client("dynamodb") return client.delete_item( TableName="Messages", Key={ "Date": {"S": "2021/11/28"}, }, ) def reserve_deleting_object(self, key: str): self.objects_to_delete.append(key) def delete_objects_from_s3_bucket(self): client = boto3.client("s3") client.delete_objects( Bucket=self.bucket_name, Delete={ "Objects": [{"Key": k} for k in self.objects_to_delete], }, ) @classmethod def get_and_verify_stack_name(cls) -> str: stack_name = os.environ.get("AWS_SAM_STACK_NAME") if not stack_name: raise Exception( "Cannot find env var AWS_SAM_STACK_NAME. \n" "Please setup this environment variable with the stack name where we are running integration tests." ) # Verify stack exists client = boto3.client("cloudformation") try: client.describe_stacks(StackName=stack_name) except Exception as e: raise Exception( f"Cannot find stack {stack_name}. \n" f'Please make sure stack with the name "{stack_name}" exists.' ) from e return stack_name @classmethod def _retrieve_resource_by_logical_resource_id( cls, resources: List[Dict], logical_resource_id: str ) -> List[Dict]: return [ resource for resource in resources if resource["LogicalResourceId"] == logical_resource_id ] @classmethod def collect_resources(cls) -> None: stack_name = "simple-serverless-batch" client = boto3.client("cloudformation") response = client.list_stack_resources(StackName=stack_name) resources = response["StackResourceSummaries"] state_machine_resources = cls._retrieve_resource_by_logical_resource_id( resources, "MakeReportStateMachine" ) if not state_machine_resources: raise Exception("Cannot find MakeReportStateMachine.") messages_table_resources = cls._retrieve_resource_by_logical_resource_id( resources, "MessagesTable" ) if not messages_table_resources: raise Exception("Cannot find MessagesTable.") event_rule_resources = cls._retrieve_resource_by_logical_resource_id( resources, "CallStateMachine" ) if not event_rule_resources: raise Exception("Cannot find CallStateMachine.") cls.state_machine_arn = state_machine_resources[0]["PhysicalResourceId"] cls.messages_table_name = messages_table_resources[0]["PhysicalResourceId"] cls.event_rule_name = event_rule_resources[0]["PhysicalResourceId"] response = client.describe_stacks(StackName=stack_name) bucket_name_param = [ p for p in response["Stacks"][0]["Parameters"] if p["ParameterKey"] == "S3BucketName" ] if not bucket_name_param: raise Exception("Cannot find parameter named S3BucketName") cls.bucket_name = bucket_name_param[0]["ParameterValue"] @classmethod def setUpClass(cls) -> None: cls.collect_resources() def setUp(self) -> None: self.client = boto3.client("stepfunctions") self.dummy_message = str(uuid4()) self.put_item_for_test() def tearDown(self) -> None: self.delete_item_from_dynamodb_table() self.delete_objects_from_s3_bucket() def _verify_event_rule(self) -> None: client = boto3.client("events") rule = client.describe_rule(Name=self.event_rule_name) self.assertEqual( rule["ScheduleExpression"], "cron(0 10 ? * MON-FRI *)", "This schedule does not follow the specifications.", ) self.assertEqual( rule["State"], "ENABLED", "This rule must be enabled.", ) response = client.list_targets_by_rule(Rule=self.event_rule_name) self.assertEqual( response["Targets"][0]["Arn"], self.state_machine_arn, "The StateMachine is not called by this rule.", ) def _start_execute(self) -> str: """ Start the state machine execution request and record the execution ARN """ response = self.client.start_execution( stateMachineArn=self.state_machine_arn, name=f"integ-test-{uuid4()}", input="{}", ) return response["executionArn"] def _wait_execution(self, execution_arn: str): while True: response = self.client.describe_execution(executionArn=execution_arn) status = response["status"] if status == "SUCCEEDED": logging.info(f"Execution {execution_arn} completely successfully.") break elif status == "RUNNING": logging.info(f"Execution {execution_arn} is still running, waiting") sleep(3) else: self.fail(f"Execution {execution_arn} failed with status {status}") def _retrieve_convert_html_to_pdf_input(self, execution_arn: str) -> Dict: response = self.client.get_execution_history(executionArn=execution_arn) events = response["events"] convert_html_to_pdf_entered_event = [ event for event in events if event["type"] == "TaskStateEntered" and event["stateEnteredEventDetails"]["name"] == "Convert Html to Pdf" ] input = json.loads( convert_html_to_pdf_entered_event[0]["stateEnteredEventDetails"]["input"] ) self.reserve_deleting_object(input["ObjectName"]) return input def _retrieve_convert_html_to_pdf_output(self, execution_arn: str) -> Dict: response = self.client.get_execution_history(executionArn=execution_arn) events = response["events"] convert_html_to_pdf_entered_event = [ event for event in events if event["type"] == "TaskStateExited" and event["stateExitedEventDetails"]["name"] == "Convert Html to Pdf" ] output = json.loads( convert_html_to_pdf_entered_event[0]["stateExitedEventDetails"]["output"] ) self.reserve_deleting_object(output["ObjectName"]) return output def _verify_convert_html_to_pdf_input(self, input: Dict) -> None: expected_object_name = "2021_11_28.html" self.assertDictEqual( input, { "BucketName": self.bucket_name, "ObjectName": expected_object_name, }, ) self.assert_object_exists(self.bucket_name, expected_object_name) def _verify_convert_html_to_pdf_output(self, output: Dict) -> None: expected_object_name = "2021_11_28.pdf" self.assertDictEqual( output, { "BucketName": self.bucket_name, "ObjectName": expected_object_name, }, ) self.assert_object_exists(self.bucket_name, expected_object_name) def test_state_machine(self): self._verify_event_rule() execution_arn = self._start_execute() self._wait_execution(execution_arn) input = self._retrieve_convert_html_to_pdf_input(execution_arn) self._verify_convert_html_to_pdf_input(input) output = self._retrieve_convert_html_to_pdf_output(execution_arn) self._verify_convert_html_to_pdf_output(output)
Integrationテストの実行
まずは、以下のコマンドでデプロイしておきましょう。
sam deploy --config-file ./samconfig.toml
※デプロイが完了するまで待機してください。
※すでにデプロイ済みの場合は、DynamoDBやS3をバケットを空にしておくと良いでしょう。
では、さっそくテストを実行しましょう。
ソースコードにもありますが、AWS_SAM_STACK_NAMEという環境変数が定義されている必要があります。
ここでは、実行時に一時的に設定するようにしましょう。
AWS_SAM_STACK_NAME="simple-serverless-batch" python -m pytest tests/integration -v
エラーなく実行されれば完成です。
問題が無いことが確認できたら、料金がかかるのを防ぐため、忘れずに今回のハンズオンで使ったAWSリソースを全て削除してください。
aws cloudformation delete-stack \ --stack-name simple-serverless-batch
まとめ
お疲れ様でした。
今回は全5章に渡ってAWSを使ったシンプルなバッチをサーバーレスで開発してきましたが、これで完成となります。
小さいサンプルながら
- EventBridgeやStepFunctionなどの多彩なAWSリソースの連帯
- Lambdaレイヤー
templateの書き型- ソフトウェアのアーキテクチャ
- ユニットテストとIntegrationテスト
まで、さまざまな点を考慮した実装を行いました。
Lambdaで行えるバッチ処理はシンプルなものに限られますがSAMを使って手早く実装できるとAWS活用の幅がぐっと広がってきます。
そして、なにより運用コストが安い点も魅力ですよね。
今回触れた内容はバッチ処理にかかわらず応用できる部分がたくさんあるはずです。
ここまで一緒に試してくれてありがとうございました。
ここで触れた技術が皆様の実際の開発で役に立てば幸いです。