この記事ではPostgreSQLでピボットテーブルを行う方法を紹介します。
ピボットテーブルを知らない人も読めます。
crosstabの使い方をメインに紹介しつつ、代替えとしてcrosstabを使わない方法も紹介します。

ピボットテーブルとは?
ピボットテーブルとは、あるテーブル(表)を元にして新しい分析用のテーブルを生成する機能です。
既存のテーブルに対して、以下の操作を行います。
- 行と列を入れ替える。
- とある列の値を列項目として抽出する。
- データをグループごとに集計する。
この機能はExcelやGoogleスプレッドシートでも使えます。
実際の例を見てみましょう。
以下はある学校の定期テストの結果を表すテーブルです。
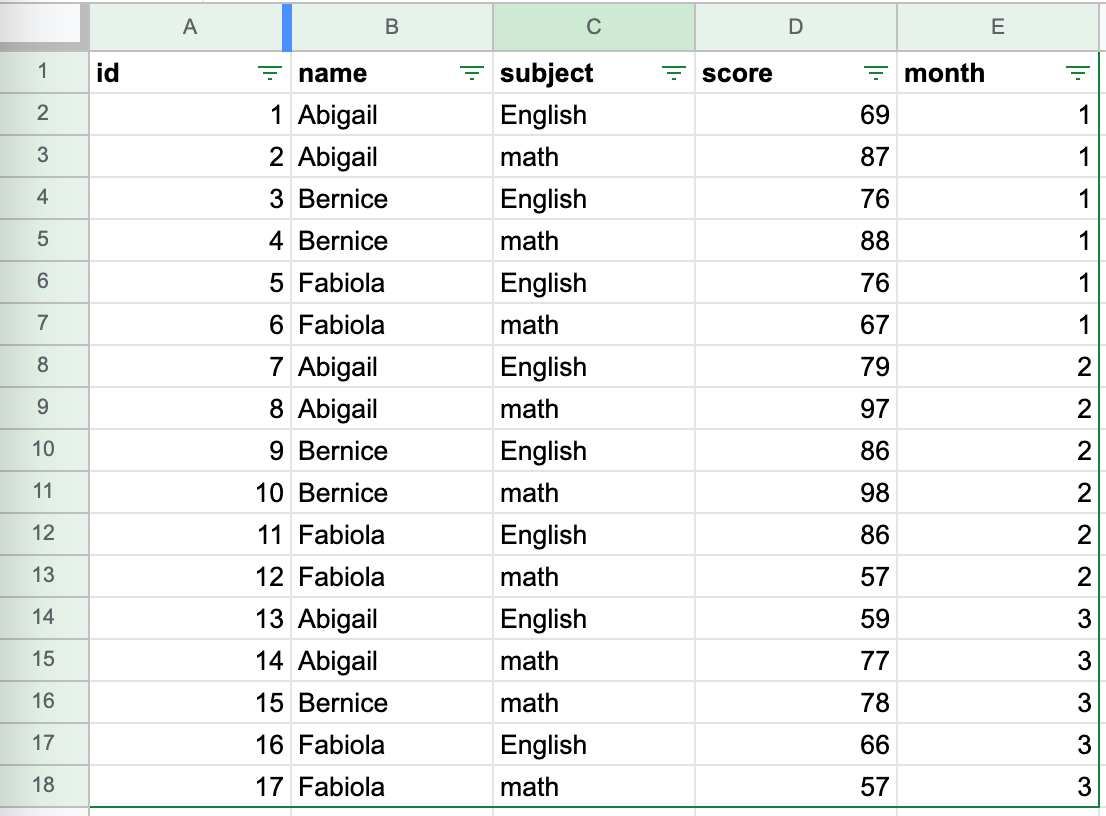
3人分の生徒に対する、全3回分の英語(English)および数学(math)のテスト結果が入っています。
では、それぞれの学生に対して英語、数学の平均点を知りたいとします。
ピボットテーブルを使えば、次のようなテーブルを簡単に作れます。

このテーブルは、以下のように元のテーブルを変換したものです。
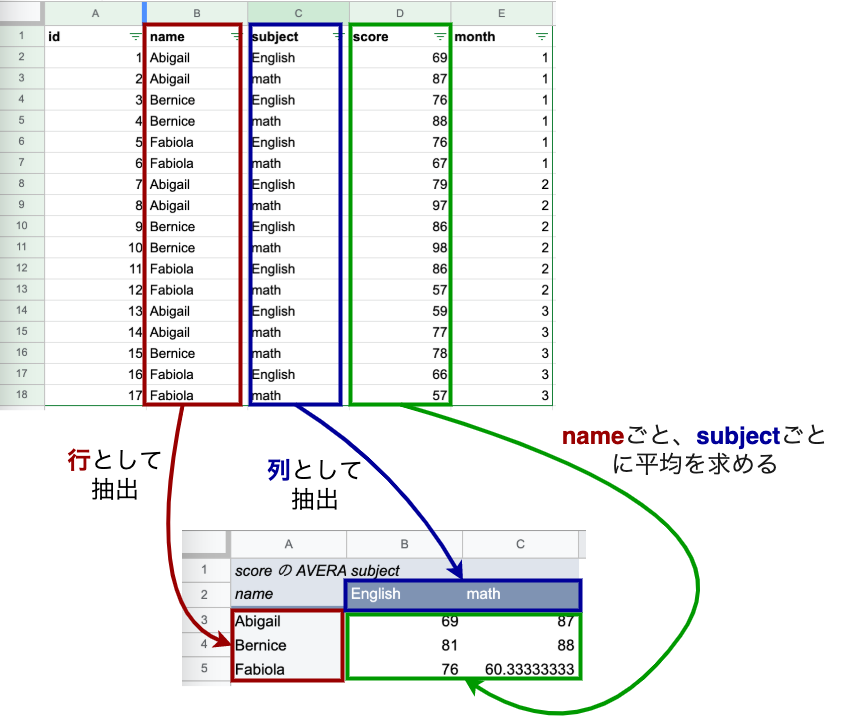
今回は、このような処理をPostgreSQLで実現するためのクエリを見ていきます。
今回使うテーブル
今回は以下のように、テストの結果を表すテーブルを使います。
| id | name | class | subject | score |
|---|---|---|---|---|
| 1 | Abigail | A | math | 50 |
| 2 | Abigail | A | English | 72 |
| 3 | Bernice | A | math | 96 |
| 4 | Bernice | A | English | 74 |
| 5 | Fabiola | A | math | 66 |
| 6 | Fabiola | A | English | 65 |
| 7 | Golda | B | math | 51 |
| 8 | Golda | B | English | 65 |
| 9 | Hardy | B | math | 85 |
| 10 | Hardy | B | English | 69 |
| 11 | Jaylan | B | math | 53 |
| 12 | Jaylan | B | English | 76 |
| 13 | Jeromy | C | math | 44 |
| 14 | Jeromy | C | English | 77 |
| 15 | Larissa | C | math | 56 |
| 16 | Larissa | C | English | 56 |
| 17 | Myriam | C | math | 52 |
| 18 | Myriam | C | English | 68 |
それぞれのカラムの説明は以下の通りです。
| カラム名 | 説明 |
|---|---|
| id | 主キー用のただの連番 |
| name | 生徒名 |
| class | クラス(A組、B組、C組) |
| subject | 教科名 |
| score | 点数 |
DDL
手元で実行してみたい人のために、DDLを載せます。コピーして使ってください。
CREATE TABLE test_result ( id SERIAL PRIMARY KEY, name TEXT NOT NULL, class VARCHAR(1) NOT NULL, subject TEXT NOT NULL, score INT NOT NULL );
テストデータ
今回利用するテストデータです。こちらも必要に応じてコピーして使ってください。
INSERT INTO test_result (name, class, subject, score) VALUES ('Abigail','A','math',50), ('Abigail','A','English',72), ('Bernice','A','math',96), ('Bernice','A','English',74), ('Fabiola','A','math',66), ('Fabiola','A','English',65), ('Golda','B','math',51), ('Golda','B','English',65), ('Hardy','B','math',85), ('Hardy','B','English',69), ('Jaylan','B','math',53), ('Jaylan','B','English',76), ('Jeromy','C','math',44), ('Jeromy','C','English',77), ('Larissa','C','math',56), ('Larissa','C','English',56), ('Myriam','C','math',52), ('Myriam','C','English',68);
docker-compose.yaml
手元で実行するためにPostgreSQLサーバを立ち上げたい人は、以下のdocker-compose.yamlをコピーして使ってください。
version: "3" services: db: image: postgres restart: always environment: POSTGRES_PASSWORD: postgres POSTGRES_USER: postgres POSTGRES_DB: postgres ports: - "5432:5432"
※今回はPostgreSQLが提供するcrosstabという関数を利用するのですが、これにはEXTENSIONの作成が必要です。
そのため、db-fiddleのようにブラウザから実行する類いのサービスは利用できないようでした。
作りたいテーブル
今回は先ほどのテーブルを元に、クラスごとの、教科ごとの平均点を求めましょう。
つまり、以下のようなテーブルをSQLにより生成する、ということです。
| class | english | math |
|---|---|---|
| A | 70.3333333333333333 | 70.6666666666666667 |
| B | 70 | 63 |
| C | 67 | 50.6666666666666667 |
これには3つ方法があります。
crosstabを使う方法サブクエリを使う方法CASE式を使う方法
この記事では、crosstabをメインに解説しますが、おまけとしてサブクエリを使う方法と CASE式を使う方法も紹介します。
では、それぞれ見ていきます。
crosstabを使う
crosstabはPostgreSQLにおけるピボットテーブルを生成する関数です。
ピボットテーブル用の関数をcrosstabを使っていきましょう。
crosstabを使う事前準備
crosstabを利用するには拡張機能をロードしておく必要があります。
今回利用しているデータベースで予め以下のクエリを実行しておきます。
CREATE EXTENSION IF NOT EXISTS tablefunc;
crosstabを使ったピボットテーブル
では早速crosstabを使ってみましょう。以下のようになります。
SELECT * FROM crosstab( 'SELECT class, subject, AVG(score) FROM test_result GROUP BY class, subject ORDER BY 1, 2' ) AS pvt( class VARCHAR(1), English NUMERIC, math NUMERIC );
crosstab はレコードのセット(setof record)を返す関数です。そのため、FROMに書きます。
つづいて、crosstabの引数に注目しましょう。SQLが文字列として渡されていますね。
crosstabでは、この「文字列で渡されたSQL」がとても重要です。
crosstabの引数
では、この文字列のSQLはどんなものか見ていきます。
これは、言うなれば「ピボットテーブルを作成するにあたり、必要なデータを抽出するクエリ」です。

では、このクエリについてもっと詳しく見ていきます。
SELECT class, subject, AVG(score) FROM test_result GROUP BY class, subject ORDER BY 1, 2
crosstabは内部でこのクエリの実行結果を使います。
そのため、どのようなクエリを渡すかは決まっています。「こんなクエリを渡してね」という風にcrosstabから要求されているイメージです。
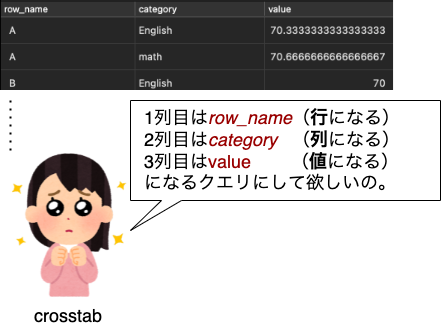
crosstabに渡すクエリは以下の3つのカラムをSELECTするものでなければなりません。
- 1列目は、行として抽出するカラムです。公式ドキュメントでは
row_nameといいます。今回はclassを指定しました。これは「クラスごと」に平均を求めるからです。 - 2列目は、列として抽出するカラムです。 公式ドキュメントでは
categoryといいます。 今回はsubjectを指定しました。これは「クラスごと、教科ごと」に平均を求めるからです。 - 3列目は、値です。公式ドキュメントでは
valueといいます。今回はscoreの平均ですので、AVG(score)を指定しました。
改めて図解で確認してみましょう。
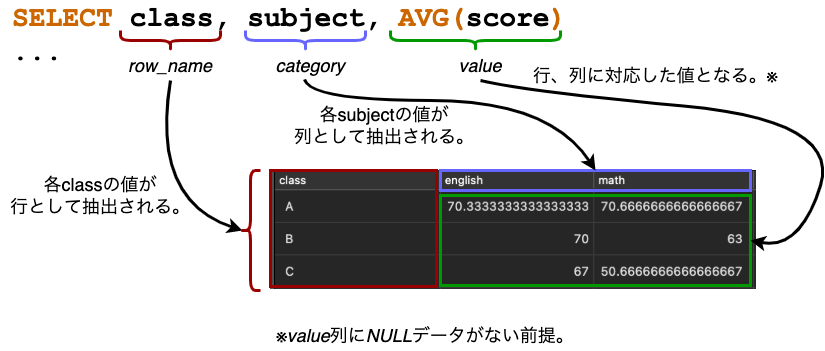
そして、事実上ORDER BY 1, 2つまり、ORDER BY row_name, categoryは必須です。
ORDER BY 1つまりORDER BY row_nameについては、crosstabは連続した値を1つの行として抽出するためです。
「row_nameの値を確実に連続させる」には、「row_nameでソートする」必要があります。

uniqコマンドで重複行を削除するためには、入力データが事前にソートされていないといけないことを思い出してください。sort | uniq。ここでORDER BY 1をするのはこれと同じ理由です。
ORDER BY 2つまりORDER BY categoryについては、row_name間でcategoryが同じ順番で列ぶようにする必要があるからです。
また、categoryがどの順番で現れるかが予測できないと、crosstabの結果となるカラムを定義する際に困ります。
例えば、今回はcrosstabの結果をpvtとしています。
SELECT * FROM crosstab('...省略...') AS pvt( class VARCHAR(1), English NUMERIC, math NUMERIC );
この定義に注目します。
pvt( class VARCHAR(1), English NUMERIC, math NUMERIC );
ここで、2列目はEnglish、3列目はmathと定義していますが、これはcategoryであるsubjectがアルファベットごとに昇順にソートされている前提です。
PostgreSQL側でpvtのカラム名とsubjectの値を比較してよしなに並べてくれる訳ではありません。
上記のように、crosstabは文字列で指定したSQLを実行し、その結果をもとにピボットテーブルを作って返してくれています。
crosstabの落とし穴
crosstabには落とし穴が存在します。幸い、今回の例では問題になりませんでした。
この落とし穴が危険なのは、特定のrow_nameにおいて、対応するcateogryが存在しない場合です。
具体例を見てみましょう。
テーブルの準備
次は以下のようなテーブルを使います。
毎月の定期テストの結果を格納するテーブルです。
| id | name | subject | score | month |
|---|---|---|---|---|
| 1 | Abigail | English | 69 | 1 |
| 2 | Abigail | math | 87 | 1 |
| 3 | Bernice | English | 76 | 1 |
| 4 | Bernice | math | 88 | 1 |
| 5 | Fabiola | English | 76 | 1 |
| 6 | Fabiola | math | 67 | 1 |
| 7 | Abigail | English | 79 | 2 |
| 8 | Abigail | math | 97 | 2 |
| 9 | Bernice | English | 86 | 2 |
| 10 | Bernice | math | 98 | 2 |
| 11 | Fabiola | English | 86 | 2 |
| 12 | Fabiola | math | 57 | 2 |
| 13 | Abigail | English | 59 | 3 |
| 14 | Abigail | math | 77 | 3 |
| 15 | Bernice | math | 78 | 3 |
| 16 | Fabiola | English | 66 | 3 |
| 17 | Fabiola | math | 57 | 3 |
新しくテーブルを作ります。
CREATE TABLE regular_test( id SERIAL PRIMARY KEY, name TEXT NOT NULL, subject TEXT NOT NULL, score INT NOT NULL, month INT NOT NULL );
データを投入します。
INSERT INTO regular_test(name, subject, score, month) VALUES ('Abigail', 'English', 69, 1), ('Abigail', 'math' , 87, 1), ('Bernice', 'English', 76, 1), ('Bernice', 'math' , 88, 1), ('Fabiola', 'English', 76, 1), ('Fabiola', 'math' , 67, 1), ('Abigail', 'English', 79, 2), ('Abigail', 'math' , 97, 2), ('Bernice', 'English', 86, 2), ('Bernice', 'math' , 98, 2), ('Fabiola', 'English', 86, 2), ('Fabiola', 'math' , 57, 2), ('Abigail', 'English', 59, 3), ('Abigail', 'math' , 77, 3), --('Bernice', 'English', 66, 3), <------- 欠損 ('Bernice', 'math' , 78, 3), ('Fabiola', 'English', 66, 3), ('Fabiola', 'math' , 57, 3);
上記のクエリでBerniceさんのEnglishがコメントアウトされている点に注意してください。
つまり、Berniceさんは3月のEnglishのテストを受験しなかったということです。
落とし穴
では、このテーブルから、3月の生徒ごと、教科ごとの点数をテーブル化します。
以下のようなクエリになります。(今回は集計は不要です。)
SELECT * FROM crosstab(' SELECT name, subject, score FROM regular_test WHERE month = 3 ORDER BY 1, 2 ') AS pvt ( name TEXT, English INT, math INT )
結果は以下のようになります。BerniceさんのEnglishの点数はどうなっているかに注目してください。
| name | english | math |
|---|---|---|
| Abigail | 59 | 77 |
| Bernice | 78 | NULL |
| Fabiola | 66 | 57 |
Berniceさんの3月のEnglishの点数は78点として扱われています。
一方で、受験したはずのmathの点数はNULLになっています。
これが落とし穴です。crosstabはcategoryとvalueの整合性をチェックせず、結果テーブルに対して、左から順番に機械的にvalueを格納します。

引数2つのcrosstabで落とし穴を回避
これを解決するには、引数が2つあるcrosstabを使います。
最初の引数はこれまでと同じです(後述するが、少し拡張できる)。
次の引数は、categoryの一覧を抽出するSQL(文字列)です。
これを使うと以下のように書けます。
SELECT * FROM crosstab( 'SELECT name, subject, score FROM regular_test WHERE month = 3 ORDER BY 1, 2', 'SELECT DISTINCT subject FROM regular_test ORDER BY 1' ) AS pvt ( name TEXT, English INT, math INT );
結果は次のようになります。
| name | english | math |
|---|---|---|
| Abigail | 59 | 77 |
| Bernice | NULL | 78 |
| Fabiola | 66 | 57 |
BerniceさんのEnglishがNULLになっていますね。
crosstabの2つめの引数SELECT DISTINCT subject FROM regular_test ORDER BY 1が、教科の一覧(categoryの一覧)を取得するクエリです。
全てのcategoryを得るクエリをcrosstabに渡すことで、欠損しているデータも期待通り処理してくれます。
このように、引数が2つのcrosstabを使うことで、この落とし穴を回避できます。
引数2つのcrosstabはカラムを追加できる
また、引数が2つのcrosstabでは、追加カラムを持つことができます。
1番目の引数のクエリを思い出しましょう。引数が1つのcrosstabでは3つのカラム(row_name、category、value)しか指定できませんでした。
一方で、引数が2つのcrosstabではカラムを追加できます。ただし、この追加のカラムの値はrow_nameで指定した項目と1対1で対応している必要があります。
row_nameでGROUP BYした時にただ一つに値が定まる必要があるからですね。
ここでは、最初に使ったtest_resultテーブルを使い、各生徒の教科ごとのスコアを見てみましょう(集計しない)。それにclassの情報を追加します。
今回の例ではrow_nameであるnameと追加カラムであるclassは1対1で紐付いています。
※Abigailは常にA組ですよね。
SELECT * FROM crosstab( ' SELECT name, class, subject, AVG(score) FROM test_result GROUP BY class, name, subject ORDER BY 1 ', 'SELECT DISTINCT subject FROM test_result ORDER BY 1' ) AS pvt ( name TEXT, class VARCHAR(1), English NUMERIC, math NUMERIC );
結果は以下のようになります。
| name | class | english | math |
|---|---|---|---|
| Abigail | A | 72 | 50 |
| Bernice | A | 74 | 96 |
| Fabiola | A | 65 | 66 |
| Golda | B | 65 | 51 |
| Hardy | B | 69 | 85 |
| Jaylan | B | 76 | 53 |
| Jeromy | C | 77 | 44 |
| Larissa | C | 56 | 56 |
| Myriam | C | 68 | 52 |
追加カラムは複数とれますが、ルールが存在します。
- 先頭カラムは必ず
row_nameにする。 - 末尾は必ず
category、valueの順番にする。

サブクエリを使う方法
crosstabを使わずに、サブクエリを使って「作りたいテーブル」にあるクラスごとの、教科ごとの平均点を求めましょう。
以下のようにSELECTでサブクエリを使うことで、目的のテーブルを作成できます。
SELECT cl.class, (SELECT AVG(score) FROM test_result WHERE subject = 'English' AND class = cl.class) AS English, (SELECT AVG(score) FROM test_result WHERE subject = 'math' AND class = cl.class) AS math FROM (SELECT DISTINCT(class) FROM test_result ORDER BY 1) cl ORDER BY 1;
結果は以下のようになります。
| class | english | math |
|---|---|---|
| A | 70.3333333333333333 | 70.6666666666666667 |
| B | 70 | 63 |
| C | 67 | 50.6666666666666667 |
ポイントはFROMでクラスの一覧を取得し、それに対してSELECTに書かれたサブクエリが1行ごとに実行される、ということですね。

CASE式を使う方法
先ほどはサブクエリを使いましたが、CASE式を使う方法もあります。
SELECT tr.class, AVG(CASE WHEN tr.subject = 'English' THEN tr.score END) AS English, AVG(CASE WHEN tr.subject = 'math' THEN tr.score END) AS math FROM test_result tr GROUP BY 1 ORDER BY 1
結果は以下のようになります。
| class | english | math |
|---|---|---|
| A | 70.3333333333333333 | 70.6666666666666667 |
| B | 70 | 63 |
| C | 67 | 50.6666666666666667 |
こちらはclassでグループ化している点に注意してください。
グループごとにAVGを使うのはグループ化のよくあるパターンです。しかし、値の選択にCASE式が使われています。
読み解くに当たって、AVGおよびCASE式の仕様を確認してください。
まず1つは、AVGはNULLのデータを無視するということです。(データ数としてカウントしないということです。)
WITH data(v) AS ( VALUES (1::integer), (2), (3), (NULL) ) SELECT AVG(v) FROM data
上記クエリの結果は2になりますから、NULLが無視されているのが分かりますね。
次に、CASE式はELSEを省略するとNULLに評価されるということです。
SELECT (CASE WHEN 1 = 1 THEN 'yes' END) AS expect_yes, (CASE WHEN 1 = 2 THEN 'yes' END) AS expect_null, (CASE WHEN 1 = 3 THEN 'yes' ELSE 'no' END) AS expect_no
結果は以下のようになります。
| expect_yes | expect_null | expect_no |
|---|---|---|
| yes | NULL | no |
これら2つを踏まえると、このクエリが動作する理由が分かってきますよね。
まとめ
PostgreSQLでピボットテーブルをするにはcrosstabという関数を使う。
しかし、それができない環境などではサブクエリやCASE式で目的のテーブルを作成することが可能。
余談:SQL ServerのPIVOT演算子
PostgreSQLでは「SQLを文字列リテラルで渡す」というちょっと「違和感」のある実装になっていますね。
もちろん、機能として実現されているので全く問題はありません。
しかし、SQL Serverにはピボットテーブルを行うためのPIVOT演算子が用意されているようです。
これを使うと、crosstabにあったような「落とし穴」もありません。
ドキュメントを参考に書いてみました。とても洗練されている演算子ですね。(もちろん動作確認済み。)
SELECT name, English, math FROM ( SELECT name, subject, score FROM regular_test WHERE month = 3 ) AS source PIVOT ( MAX(score) FOR subject IN ([English], [math]) ) AS pvt;
詳しくは以下の公式ドキュメントを参照してください。