
pandasに入門したのですが、SQLを知っていると割とサクサク学習できた印象でした。
そこで、SQLでやっていた「あれこれ」をpandasでやるとどうなるの?という視点でpandasの基本的な使い方をまとめてみました。
はじめに
コードを実行する前にNumPyとpandasをimportしておきます。
import numpy as np import pandas as pd
抽出(WHERE)
テーブルから条件に一致した行を抽出するクエリをpandasで書いてみます。
以下のテーブルtest_resultを例にします。
こちらは、ある学校のテストの結果です。classというカラムは、A組やB組などのクラスを表します。
| id | student | class | score |
|---|---|---|---|
| 0 | Larissa | A | 50 |
| 1 | Jaylan | B | 69 |
| 2 | Golda | A | 68 |
| 3 | Myriam | A | 70 |
| 4 | Fabiola | C | 82 |
| 5 | Abigail | C | 57 |
| 6 | Bernice | B | 88 |
| 7 | Hardy | B | 76 |
| 8 | Jeromy | C | 93 |
pandasでは、テーブルではなくDataFrameといいます。
pandasは列指向ですので、以下のようにDataFrameオブジェクトを作成します。
df = pd.DataFrame({
'student': ['Larissa', 'Jaylan', 'Golda', 'Myriam', 'Fabiola', 'Abigail', 'Bernice', 'Hardy', 'Jeromy'],
'class': list('ABAACCBBC'),
'score': [50, 69, 68, 70, 82, 57, 88, 76, 93],
})
※テーブルのidカラムはpd.DataFrame()により、自動で連番で付与されます。これはindexといいます。indexは自動で付与するのではなく、予め作成したindexオブジェクトを指定することもできます。
1つの条件で抽出
では、このデータからA組のテスト結果の点数と生徒の名前を抽出してみましょう。
SQLでやるなら、こんな感じになりますね。
SELECT id, student, class FROM test_result WHERE class == 'A'
こちらをpandasを使うと以下のように書けます。
df.loc[df['class'] == 'A', ['student', 'score']]

結果は以下のようになります。
| student | score | |
|---|---|---|
| 0 | Larissa | 50 |
| 2 | Golda | 68 |
| 3 | Myriam | 70 |
pandasでは、DataFrame.locというプロパティで行にアクセスできます。
例えば、indexが0 ~ 3の行のみ取得するには次のようにします。
df.loc[:3]
| student | class | score | |
|---|---|---|---|
| 0 | Larissa | A | 50 |
| 1 | Jaylan | B | 69 |
| 2 | Golda | A | 68 |
| 3 | Myriam | A | 70 |
※境界値である「3」の行も抽出されていることに注意してください。
このように、locは基本的にはindex(今回は0から始まる連番)の情報と比較して行を抽出します。
一方で、boolean型の配列を指定することもできます。(配列の代わりにpandasのSeriesも可)
配列を指定した場合は、Trueの行のみ抽出します。
例を見てみましょう。 以下は奇数番目のレコードのみ抽出するコードです。
df.loc[[False, True, False, True, False, True, False, True, False]]
| student | class | score | |
|---|---|---|---|
| 1 | Jaylan | B | 69 |
| 3 | Myriam | A | 70 |
| 5 | Abigail | C | 57 |
| 7 | Hardy | B | 76 |
条件に一致するレコードの抽出はこの仕組みを利用します。
「classがAである」を表すboolean配列(Series)は以下のように取得できます。
df['class'] == 'A'
結果は以下の用になります。
0 True 1 False 2 True 3 True 4 False 5 False 6 False 7 False 8 False
よって、これをlocプロパティに指定することで、「classがAである」行を抽出することができる、ということです。
df.loc[df['class'] == 'A', ['student', 'score']]

複数の条件で抽出
では、この仕組みを使って複数の抽出条件に対応するにはどうすれば良いでしょうか?
ここは古典的なAND演算、OR演算が使えそうですね。つまり、2つのboolean配列同士を演算すると言うことです。
では、「C組のうち、80点以上の生徒」という複数の条件で抽出してみましょう。
df.loc[(df['class'] == 'C') & (df['score'] >= 80)]
※真偽値の配列の演算にはandやorというキーワードは使えません。エラーになります。代わりに&、|の演算子を使います。
| student | class | score | |
|---|---|---|---|
| 4 | Fabiola | C | 82 |
| 8 | Jeromy | C | 93 |
よさそうですね。
DataFrame.locプロパティの詳細は以下のドキュメントから知ることができます。
pandas.DataFrame.loc — pandas 1.3.2 documentation
結合(JOIN)
データベースのようなテーブル同士の結合をpandasでやってみましょう。
まずは、以下のような2つのテーブルがあるとします。
studentテーブルです。
| id | name | class |
|---|---|---|
| A1 | Larissa | A |
| B1 | Jaylan | B |
| A2 | Golda | A |
| A3 | Myriam | A |
| C1 | Fabiola | C |
| C2 | Abigail | C |
| B2 | Bernice | B |
| B3 | Hardy | B |
| C4 | Jeromy | C |
以下は授業への出席を表す、attendanceテーブルです。
| id | student_id | subject |
|---|---|---|
| 0 | C2 | History |
| 1 | C1 | Japanese |
| 2 | C4 | English |
| 3 | A1 | math |
| 4 | C2 | math |
| 5 | B2 | History |
| 6 | A1 | math |
| 7 | B1 | math |
| 8 | B3 | History |
それぞれ、以下のようにDataFrameオブジェクトを作成します。
student = pd.DataFrame({
'name': ['Larissa', 'Jaylan', 'Golda', 'Myriam', 'Fabiola', 'Abigail', 'Bernice', 'Hardy', 'Jeromy'],
'class': list('ABAACCBBC'),
}, index=['A1', 'B1', 'A2', 'A3', 'C1', 'C2', 'B2', 'B3', 'C4'])
attendance = pd.DataFrame({
'student_id': ['C2', 'C1', 'C4', 'A1', 'C2', 'B2', 'A1', 'B1', 'B3'],
'subject': ['History', 'Japanese', 'English', 'math', 'math', 'History', 'math', 'math', 'History'],
})
INNER JOIN
まずは、INNER JOINを試してみましょう。
attendanceテーブルにstudentテーブルを結合して、生徒の情報を見えるようにします。
SQLでは以下のような感じです。
SELECT * FROM attendance INNER JOIN student ON attendance.student_id = student.id
pandasではこうなります。
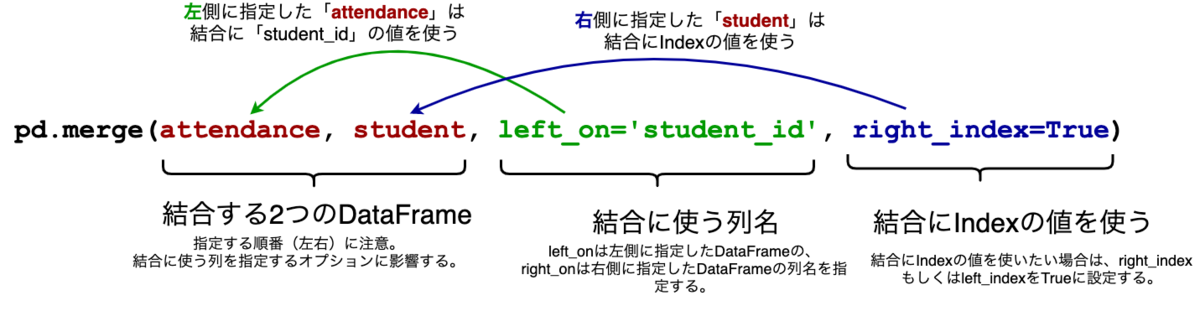
pd.merge(attendance, student, left_on='student_id', right_index=True)
| student_id | subject | name | class | |
|---|---|---|---|---|
| 0 | C2 | History | Abigail | C |
| 4 | C2 | math | Abigail | C |
| 1 | C1 | Japanese | Fabiola | C |
| 2 | C4 | English | Jeromy | C |
| 3 | A1 | math | Larissa | A |
| 6 | A1 | math | Larissa | A |
| 5 | B2 | History | Bernice | B |
| 7 | B1 | math | Jaylan | B |
| 8 | B3 | History | Hardy | B |
2つのDataFrameの結合にはpandasのmerge()を使います。
merge()では、結合に使う列名をright_onもしくはleft_onオプションで指定できます。
列ではなくIndexを結合に使う場合は、right_indexもしくはleft_indexをTrueに設定します。
LEFT JOIN
続いて、LEFT JOINをやってみましょう。
「B組の生徒について、歴史(History)への出席情報」を取得します。
SQLでは、以下のようになります。
SELECT * FROM student LEFT JOIN attendance ON student.id = attendance.student_id WHERE student.class = 'B' AND attendance.subject = 'History'
pandasでは次のようにします。
# 各DataFrameからB組、およびHistoryの出席情報をそれぞれ抽出 b_student = student.loc[student['class'] == 'B'] history_attendance = attendance.loc[attendance['subject'] == 'History'] # LEFT JOINを実行 pd.merge( b_student, history_attendance, left_index=True, right_on='student_id', how='left', ).set_index(b_student.index)
先ほどまでのコードとほとんど変わりません。
重要なポイントはhow='left'で、LEFT JOINを指定している点です。
set_index()を使うことで、b_student.indexをmerge後のIndexとして設定しています。
結果は以下のようになります。
| name | class | student_id | subject | |
|---|---|---|---|---|
| B1 | Jaylan | B | B1 | NaN |
| B2 | Bernice | B | B2 | History |
| B3 | Hardy | B | B3 | History |
IndexがB1のJaylanさんは歴史の授業に出席していないため、値がNaNになっています。(NaNはNumPyのnp.nanです。)
merge()の詳細は以下のドキュメントから知ることができます。
pandas.merge — pandas 1.3.2 documentation
集約(GROUP BY)
次に集約GROUP BYをpandasで実現する方法を見てみましょう。
以下のように、テストの結果を表すtest_resultテーブルを例にします。
| name | class | subject | score | |
|---|---|---|---|---|
| 0 | Abigail | A | math | 50 |
| 1 | Abigail | A | English | 72 |
| 2 | Bernice | A | math | 96 |
| 3 | Bernice | A | English | 74 |
| 4 | Fabiola | A | math | 66 |
| 5 | Fabiola | A | English | 65 |
| 6 | Golda | B | math | 51 |
| 7 | Golda | B | English | 65 |
| 8 | Hardy | B | math | 85 |
| 9 | Hardy | B | English | 69 |
| 10 | Jaylan | B | math | 53 |
| 11 | Jaylan | B | English | 76 |
| 12 | Jeromy | C | math | 44 |
| 13 | Jeromy | C | English | 77 |
| 14 | Larissa | C | math | 56 |
| 15 | Larissa | C | English | 56 |
| 16 | Myriam | C | math | 52 |
| 17 | Myriam | C | English | 68 |
DataFrameオブジェクトは次のようになります。
test_result = pd.DataFrame({
'name': np.sort(['Larissa', 'Jaylan', 'Golda', 'Myriam', 'Fabiola', 'Abigail', 'Bernice', 'Hardy', 'Jeromy'] * 2),
'class': np.sort(list('AABBCC') * 3),
'subject': ['math', 'English'] * 9,
'score': [50, 72, 96, 74, 66, 65, 51, 65, 85, 69, 53, 76, 44, 77, 56, 56, 52, 68],
})
集約関数が1つの場合
このテーブルから、「クラスごと、教科ごとの平均点」を求めてみます。
SQLだと、こんな感じです。
SELECT class, subject, avg(score) FROM test_result GROUP BY class, subject
pandasではDataFrameがもつgroupby()を利用します。
test_result.groupby(['class', 'subject']).mean()
結果は以下のようになります。
| class | subject | score |
|---|---|---|
| A | English | 70.333333 |
| math | 70.666667 | |
| B | English | 70.000000 |
| math | 63.000000 | |
| C | English | 67.000000 |
| math | 50.666667 |
name列が結果に表れていませんが、これは不具合ではありません。
数値ではない列は集計できないため、結果に含めない仕様になっています。
※後述しますが、この場合はピボットテーブルを使うとよりシンプルかつ直感的なテーブルが作成できます。
集約関数が複数ある場合
平均点だけで無く、最大点も表示したい場合もあるでしょう。
その場合は、DataFrameGroupByオブジェクトを有効活用します。
groupby()の結果はDataFrameGroupByというオブジェクトになります。
これのagg()メソッドを使えば複数の集約関数の結果を表示できます。
grouped = test_result.groupby(['class', 'subject']) grouped.agg(['mean', 'max'])
結果は次のようになります。
| score | |||
|---|---|---|---|
| mean | max | ||
| class | subject | ||
| A | English | 70.333333 | 74 |
| math | 70.666667 | 96 | |
| B | English | 70.000000 | 76 |
| math | 63.000000 | 85 | |
| C | English | 67.000000 | 77 |
| math | 50.666667 | 56 | |
agg()に渡す配列には、関数の名前(文字列)や関数そのもの(lambda式もOK)を複数していできます。
agg()の詳細はドキュメントを参照してください。
pandas.DataFrame.agg — pandas 1.3.2 documentation
ランキングを求める
続いて、ランキングを求めてみます。
クラスごと、教科ごとの順位を表示してみましょう。
SQLでは次のようになります。
SELECT id, name, class, subject, score, RANK() OVER (PARTITION BY class, subject ORDER BY score DESC) FROM test_result ORDER BY id;
これをpandasで実行すると以下のようになります。
grouped = test_result.groupby(['class', 'subject']) ranking = grouped['score'].rank(ascending=False, method='min') ranking.name = 'score_ranking' test_result.join(ranking)
結果は以下のようになります。
| name | class | subject | score | score_ranking | |
|---|---|---|---|---|---|
| 0 | Abigail | A | math | 50 | 3.0 |
| 1 | Abigail | A | English | 72 | 2.0 |
| 2 | Bernice | A | math | 96 | 1.0 |
| 3 | Bernice | A | English | 74 | 1.0 |
| 4 | Fabiola | A | math | 66 | 2.0 |
| 5 | Fabiola | A | English | 65 | 3.0 |
| 6 | Golda | B | math | 51 | 3.0 |
| 7 | Golda | B | English | 65 | 3.0 |
| 8 | Hardy | B | math | 85 | 1.0 |
| 9 | Hardy | B | English | 69 | 2.0 |
| 10 | Jaylan | B | math | 53 | 2.0 |
| 11 | Jaylan | B | English | 76 | 1.0 |
| 12 | Jeromy | C | math | 44 | 3.0 |
| 13 | Jeromy | C | English | 77 | 1.0 |
| 14 | Larissa | C | math | 56 | 1.0 |
| 15 | Larissa | C | English | 56 | 3.0 |
| 16 | Myriam | C | math | 52 | 2.0 |
| 17 | Myriam | C | English | 68 | 2.0 |
実際に順位を求めているのはrank(ascending=False, method='min')です。
今回は値が大きいものから順に順位を決定したいので、ascending=Falseを指定します。
さらに、method='min'を指定していますが、これはタイ(同順位)だった場合の順位の決め方を指定します。
今回はminなので、データが同じだった場合は最小の順位をつけます。
小さい例を見てみましょう。
pd.Series([10, 10, 6, 5, 5, 5, 4]).rank(ascending=False, method='min')
この結果は以下のようになります。
0 1.0 1 1.0 2 3.0 3 4.0 4 4.0 5 4.0 6 7.0 dtype: float6
点数が同じ場合は、最小の順位になっているのが分かります。(最大は10点で、それが2つある。どちらも1位扱い。次に6点が続くが、3位扱い。)
ちなみに、methodは省略するとデフォルトのaverageになります。
タイだったランキングの平均値になります。
pandas.DataFrame.rank — pandas 1.3.2 documentation
ウィンドウ関数(OVER、PARTITION BY)
pandasでもSQLのウィンドウ関数のような処理を行うにはどうすれば良いか書いていきます。
まず、以下のように、月ごとの新規登録会員数を表すテーブルを考えます。
| created_at | register | |
|---|---|---|
| 0 | 2021-02-01 | 100 |
| 1 | 2021-03-01 | 200 |
| 2 | 2021-04-01 | 300 |
| 3 | 2021-05-01 | 400 |
| 4 | 2021-06-01 | 500 |
| 5 | 2021-07-01 | 600 |
| 6 | 2021-08-01 | 700 |
| 7 | 2021-09-01 | 800 |
| 8 | 2021-10-01 | 900 |
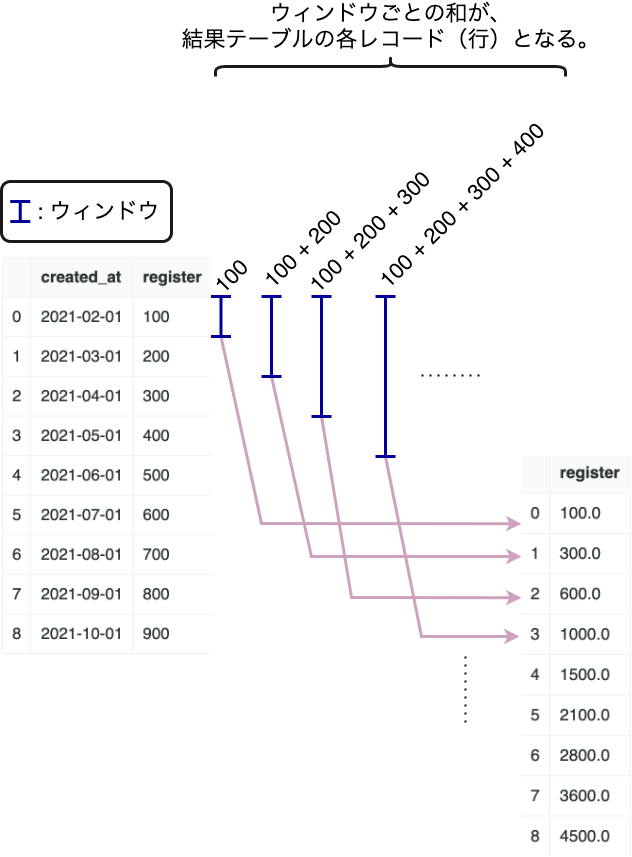
このテーブルから、月ごとの累計会員数を求めてみましょう。つまり、移動和を求めたいと言うことですね。
具体的には、以下のように、moving_sumを求めたいということですね。
| created_at | register | moving_sum |
|---|---|---|
| 2020-02-01 00:00:00 | 100 | 100 |
| 2020-03-01 00:00:00 | 200 | 300 |
| 2020-04-01 00:00:00 | 300 | 600 |
| 2020-05-01 00:00:00 | 400 | 1000 |
| 2020-06-01 00:00:00 | 500 | 1500 |
| 2020-07-01 00:00:00 | 600 | 2100 |
| 2020-08-01 00:00:00 | 700 | 2800 |
| 2020-09-01 00:00:00 | 800 | 3600 |
| 2020-10-01 00:00:00 | 900 | 4500 |
SQLでこれを実現するには以下のようにクエリを書きます。(テーブル名をkpiとしています。)
SELECT created_at, register, SUM(register) OVER (ORDER BY created_at) AS moving_sum FROM kpi;
では、これをpandasで実現してみましょう。
expanding()
pandasでは、expanding()というメソッドを使って移動和を計算することができます。
まずは、DataFrameを定義します。
df = pd.DataFrame({
'created_at': pd.date_range('2021-01-02', freq="MS", periods=9),
'register': (np.arange(9) + 1) * 100,
})
そして、以下のコードで移動和を求めます。
df.expanding().sum()
結果は以下のようになります。
| register | |
|---|---|
| 0 | 100.0 |
| 1 | 300.0 |
| 2 | 600.0 |
| 3 | 1000.0 |
| 4 | 1500.0 |
| 5 | 2100.0 |
| 6 | 2800.0 |
| 7 | 3600.0 |
| 8 | 4500.0 |
expandingと言う名前のように、ウィンドウ(窓)のサイズが広がっていくイメージです。
pandas.DataFrame.expanding — pandas 1.3.2 documentation
※今回はpandasを使いましたが、このように単純な移動和を求めるのであればNumPyのcumsum()を使えます。
df['register'].cumsum()
numpy.ndarray.cumsum — NumPy v1.21 Manual
rolling()
expanding()はウィンドウを広げていき、各ウィンドウごとに値を集約することができました。
一方、rolling()を使うと、ウィンドウのサイズを固定できます。
先ほどのデータで、2ヶ月ごとの平均新規会員数を求めてみましょう。
df.rolling(2).mean()
rolling()の引数2はウィンドウサイズです。
結果は以下のようになります。
| register | |
|---|---|
| 0 | NaN |
| 1 | 150.0 |
| 2 | 250.0 |
| 3 | 350.0 |
| 4 | 450.0 |
| 5 | 550.0 |
| 6 | 650.0 |
| 7 | 750.0 |
| 8 | 850.0 |
固定サイズのウィンドウを移動させながら平均値を求めていくイメージです。
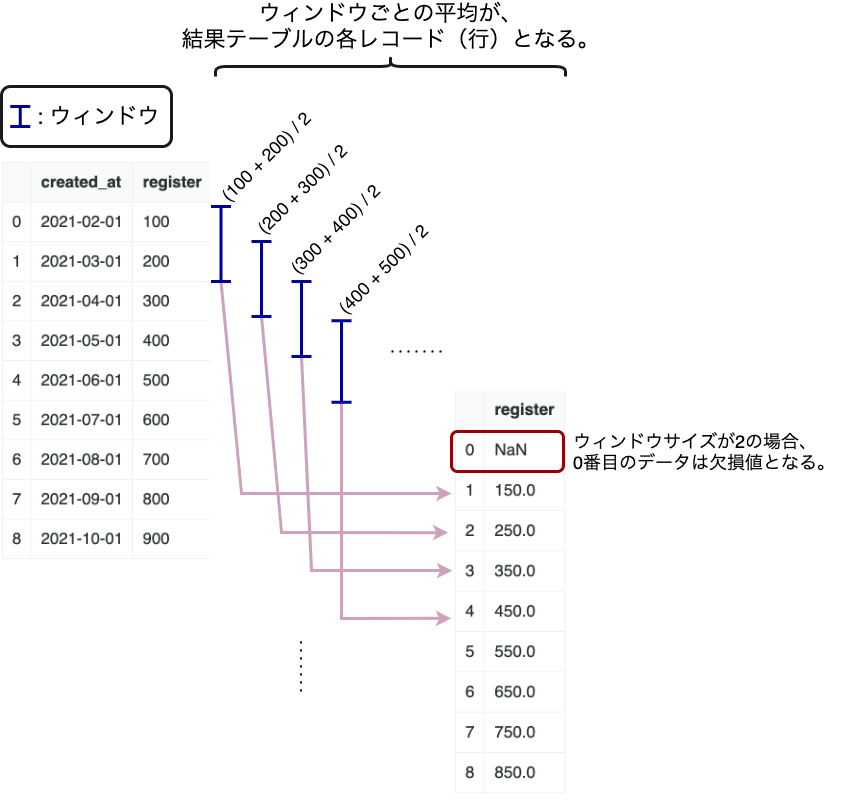
この場合、結果テーブルの0番目はNaN(欠損値)となります。
0番目のデータはサイズ2のウィンドウが作れないためです。

pandas.DataFrame.rolling — pandas 1.3.2 documentation
ピボットテーブル
先ほどはgroupby()で集約しました。これはSQLのGROUP BYに対応していて直感的です。
しかし、pandasではピボットテーブルを使うことで、もっと簡単に集計できます。
例えば、先ほど使った試験の結果テーブルを使いましょう。
| name | class | subject | score | |
|---|---|---|---|---|
| 0 | Abigail | A | math | 50 |
| 1 | Abigail | A | English | 72 |
| 2 | Bernice | A | math | 96 |
| 3 | Bernice | A | English | 74 |
| 4 | Fabiola | A | math | 66 |
| 5 | Fabiola | A | English | 65 |
| 6 | Golda | B | math | 51 |
| 7 | Golda | B | English | 65 |
| 8 | Hardy | B | math | 85 |
| 9 | Hardy | B | English | 69 |
| 10 | Jaylan | B | math | 53 |
| 11 | Jaylan | B | English | 76 |
| 12 | Jeromy | C | math | 44 |
| 13 | Jeromy | C | English | 77 |
| 14 | Larissa | C | math | 56 |
| 15 | Larissa | C | English | 56 |
| 16 | Myriam | C | math | 52 |
| 17 | Myriam | C | English | 68 |
DataFrameオブジェクトは以下でしたね。
test_result = pd.DataFrame({
'name': np.sort(['Larissa', 'Jaylan', 'Golda', 'Myriam', 'Fabiola', 'Abigail', 'Bernice', 'Hardy', 'Jeromy'] * 2),
'class': np.sort(list('AABBCC') * 3),
'subject': ['math', 'English'] * 9,
'score': [50, 72, 96, 74, 66, 65, 51, 65, 85, 69, 53, 76, 44, 77, 56, 56, 52, 68],
})
このテーブルから「クラスごと、教科ごとの平均点」をピボットテーブルを使って求めると以下のようになります。
test_result.pivot_table(
['score'],
index='class',
columns='subject',
aggfunc=np.mean
)
※実際はaggfunc=np.meanは省略可能です。aggfuncのデフォルトがnumpy.meanだからです。
結果は次のようになります。
| score | ||
|---|---|---|
| subject | English | math |
| class | ||
| A | 70.333333 | 70.666667 |
| B | 70.000000 | 63.000000 |
| C | 67.000000 | 50.666667 |
このように、pivot_table()を使えば特定の列の値をIndexにして新たなテーブルを作成できます。
その際、特定の列の値に応じて新しい階層的な列を作り、同時に集計できます。
pivot_table()を使えば、groupby()よりも直感的に分かりやすいテーブルが簡単に作れます。
pandas.pivot_table — pandas 1.3.2 documentation
感想

これまで、データ分析(といっても、ちょっと集計するくらいですが)はSQLを使って行っていました。
(恥ずかしながら、Googleフォームで送信された情報などを集計するときは、CSV化してローカルのPostgreSQLにINSERTし、SQLで使う。。。見たいなこともやっていました。)
これらの集計タスクを適当なクラウド上で自動化できないかと考えるうちに、RDBに頼らず汎用的なプログラミング言語を使いたいと思うように。
Pythonには集計(NumPyやpandas)や、データの可視化(Matplotlib)まで豊富なツールがそろっていること、加えて抽象度の高いコーディングにも適していることから、こちらに入門しました。(Pythonそのものの入門もしました。。。意外にもPythonは書いてこなかったんです。)
もっと大量のデータや詳細な分析に最適なソリューションは別にあると思います。しかし、ひとまずこれらのツールを使ってこれまでのタスクを自動化する仕組みを考えて見たいところです。
今回は新しいことを学んだつもりなのですが、SQLの知識が大分役に立ちました。
しっかり基礎を学んでいれば、新しいことを学ぶ時のベースになってくれていると実感。。。
やっぱり基礎はおろそかにできないな、、、と改めて感じました。
参考文献
今回pandasを学ぶ上で、以下の本を読みました。
本のタイトルに「データ分析」という言葉が入っていますが、実際にはpython文法、pandasやNumPy、Matplotlibを使いながらデータ分析の「方法」を解説している本です。
SQLの知識があればコードの実行結果を予想し、確認しながら読み進められます。
600ページ近くありますが、辞書的に必要な部分だけの拾い読みも可能な構成です。
